Volume 3 Issue 1 (2005) DOI:10.1349/PS1.1537-0852.A.281 Note: Linguistic Discovery uses Unicode characters to represent phonetic symbols. Please see Optimizing Display for requirements to accurately reproduce this page. A Synchronic Lexical Study of Gbe Language Varieties: The Effects of Different Similarity Judgment Criteria[1]In the context of a synchronic lexical study of the Gbe varieties of West Africa, this paper explores the question whether the use of different criteria sets to judge the similarity of lexical features in different language varieties yields the same or different conclusions regarding the relative relationships and clustering of the investigated varieties and the prioritization of further sociolinguistic research. Word lists elicited in 49 Gbe varieties were analyzed by means of the inspection method. To assess the effects of different similarity judgment criteria, two different similarity judgment criteria sets were applied to the elicited data to identify similar lexical items. The quantification of these similarity decisions resulted in the computation of two similarity matrices which were subsequently analyzed by means of correlation analysis and multidimensional scaling. The findings of the correlation analysis indicate a significant linear and positive relationship between both word-list computations, thus supporting the conclusion that application of either set of similarity judgment criteria would lead to similar clustering results for the Gbe data set. These findings are corroborated by the findings of multidimensional scaling which suggest that different sets of similarity judgment criteria lead to similar clustering results and similar conclusions as to the scope and priorities for further research. 1. IntroductionIn the context of a synchronic lexical study of the Gbe varieties of West Africa, this paper explores the question of whether the application of different sets of similarity judgment criteria in analyzing lexical features with complex polymorphemic word-structures, giving special emphasis to additional morphemes and reduplication, leads to the same or different conclusions as to the relative relationships and clustering of the investigated varieties and the prioritization of further sociolinguistic research. The Gbe language continuum (Kwa language family) is situated in the southeastern part of West Africa, occupying large areas in southern Benin, Togo, and southeastern Ghana. Among the Gbe varieties, five have thus far undergone language-based development on a larger scale. To assess whether the remaining Gbe communities could benefit from these literacy efforts or whether additional development programs in some of the remaining communities would be beneficial, a sociolinguistic study of the language continuum was launched at the end of the 1980s by the Togo-Benin branch of SIL International. During the first phase of this study, word and phrase lists were elicited in 49 Gbe varieties, to obtain a rough estimate of the computed degrees of linguistic similarity between these varieties, to identify how these varieties might be treated as clusters, and to establish priorities for further sociolinguistic research. Given the study’s overall objective of assessing the extensibility of the literacy efforts already existing, a synchronic approach was chosen for this analysis of the elicited lexical Gbe data (Kluge 2000, forthcoming). The primary tool for this approach is the inspection method, first described by Gudschinsky (1955). Focusing on phonetic similarity, this method measures the ‘relative degrees of lexical relationship’ of closely related languages as an indicator of potential intelligibility, with Gudschinsky (1956:206) concluding that knowledge of the degree of lexical similarity between language varieties “is invaluable in practical decisions regarding homogeneity of speech areas for vernacular schools, production of literature, etc.” (See also Sanders 1977, Saussure 1959, and Simons 1977). However, as Grimes (1988) points out in his study on ‘Correlations between vocabulary similarity and intelligibility,’ high degrees of lexical similarity do not correlate with a high degree of intelligibility whereas the opposite relationship does hold, in that a low degree of lexical similarity always correlates with a low degree of intelligibility. Thus, Grimes (1988) concludes that intelligibility is unlikely when lexical similarity is below 60%. Further, Grimes (1988) concludes that, although high lexical similarity degrees are not reliable, valid indicators for high intelligibility degrees, similarity degrees of above 60% are helpful in identifying areas where more in-depth studies are necessary. Following these conclusions, SIL’s ‘Language assessment criteria’ (International Language Assessment Conference 1990) gives the following recommendation for further interpretation of word-list results: [When the word-list analysis results] indicate a lexical similarity between two speech forms of less than about 70% (at the upper confidence limit of the calculation), this generally indicates that these are different languages. ... If the similarity is more than 70%, dialect intelligibility testing is needed to determine how well people can understand the other speech form. Concerning the procedures involved in making lexical similarity decisions, Gudschinsky (1956) provides a set of guidelines to identify lexical items that are both phonetically and semantically similar and to group these into sets of probable cognates. These guidelines have since been adapted for use in linguistic and sociolinguistic language surveys, for example by Blair (1990:30ff), in his manual for small-scale language surveys which provides a set of criteria for the comparison of pairs of phones in two words. These guidelines take into account word length, but do not deal with the morphemic structure of the elicited lexical items, i.e. how to handle complex polymorphemic word-structures such as additional morphemes and reduplication. Ideally though, lexical similarity decisions should be based on a thorough morphemic analysis of the elicited lexical items, isolating the equivalent basic stem morphemes in each pair of words. In the context of sociolinguistic language surveys that are limited in scope and time, however, and focus on the extensibility of potential or already existing literacy efforts, such a thorough analysis proves rather unfeasible, especially for languages with complex polymorphemic word-structures (Probst 1992, and Sanders 1977). In the context of sociolinguistic studies focusing on literacy extensibility, therefore, SIL language survey teams have been employing the inspection method in their lexical analyses to a large extent, applying the principles outlined by Blair (1990) to make similarity decisions without thorough morphemic analysis. Subsequently, SIL’s language assessment criteria are applied to the results of this analysis to establish priorities for further sociolinguistic research: if lexical similarity is higher than 70%, intelligibility testing is recommended to assess whether speakers can understand the other speech forms well enough to be able to benefit from the same literacy efforts, whereas it is assumed that speech communities sharing less than about 70% lexical similarity would not understand the other speech forms well enough to be able to benefit from the same efforts (see for example Brye and Brye 2004, Dettweiler and Dettweiler 2003, Harrison et al. 1999, and Hochstetler et al. 2004). For the analysis of the elicited lexical Gbe data, the fact that the established procedures for lexical similarity decisions take into account word length but not the morphemic structure of the elicited items raised the question how to deal with the polymorphemic word-structure, characterized by additional morphemes and reduplication, to be found in a fair number of the elicited items. Moreover, the threshold of 70% lexical similarity raised the question whether and to what extent the application of different similarity judgment criteria in analyzing these lexical items would result in differing conclusions as to the prioritization of further sociolinguistic research. Thus, in analyzing the Gbe data set, two different sets of similarity judgment criteria were applied to explore their effects on the computed degrees of lexical similarity, initial clustering of these varieties, and recommended priorities for further sociolinguistic research. (Regarding the question of whether – for the elicited Gbe word lists – the application of a synchronic approach by means of the inspection method yields comparable results to the findings of a diachronic study, conducted by Capo (1986), see Kluge (2000)). After presenting, in Section 2, pertinent background information on the Gbe language continuum, Section 3 describes the methodology employed in analyzing the elicited lexical features which resulted in the computation of two lexical similarity matrices based on the two different sets of similarity judgment criteria. Section 4 presents the findings of this analysis, focusing on the statistical relationships between both computations and the clustering of the Gbe varieties according to both criteria sets. In Section 5, the findings of this analysis are discussed with special emphasis given to the question whether the application of different similarity judgment criteria sets leads to the same or different conclusions.
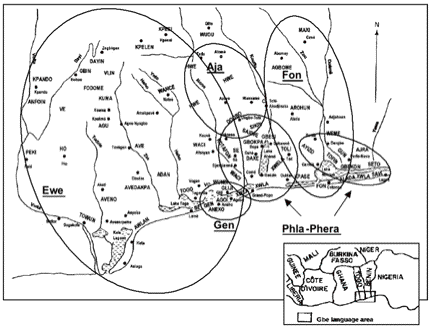
2. Background information on Gbe[2]The Gbe speech varieties are located in the southeastern part of West Africa and spoken by a total of approximately eight million speakers (estimate by Gordon 2005). Stewart (1989), revising Bennett and Sterk’s subclassification (Bennett and Sterk 1977), proposes the following classification for the Gbe language varieties: Niger-Congo, Atlantic-Congo, Volta-Congo, Kwa, Left Bank, Gbe. Based on the phonological and morphophonological characteristics of the Gbe varieties, Capo (1986; see also Capo 1991) suggests the internal classification of Gbe into five cluster: Aja, Ewe, Fon, Gen, and Phla-Phera (see also Figure 1). Listed according to their geographical location from west to east, the following varieties are assigned to each of these clusters.
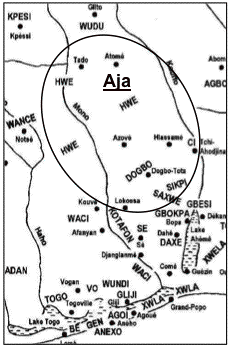
Thus far, four of the five Gbe clusters have been targeted for language-based development on a relatively large scale, Aja, Ewe, Fon, and Gen, with written materials being available in two varieties of the Fon cluster, i.e. in the Fon[3] and in the Gun varieties (Capo 1986; Direction de l’Alphabétisation 1992; Direction de l’Alphabétisation n.d., a,b,c; Direction Nationale de l’Alphabétisation n.d.; Duthie 1988). Figure 1: Map of the Gbe language area (based on Capo 1986: map 1a)3. MethodologyOn the basis of Capo’s (1986) comparative study of the Gbe language continuum, 100-word lists were elicited in 49 Gbe varieties. The word list used was based on Swadesh’s 100-word list (Swadesh 1955) and the word list published in the Atlas linguistique du Cameroun (Dieu and Renaud 1983). The analysis of the elicited 49 Gbe word lists was conducted in four steps. Step one consisted of a qualitative analysis and focused on the identification of similar lexical items. Steps two to four consisted of a quantitative analysis focusing on the computation of two similarity matrices, a paired t-test and correlation analysis, and multidimensional scaling of both matrices. In addition, a descriptive analysis was conducted to compare the findings of multidimensional scaling to the computed lexical similarity percentage matrices.
3.1 Identification of similar lexical itemsDuring this first, qualitative, part of the analysis, the elicited word lists were analyzed from a synchronic perspective applying the inspection method to determine the relative degrees of lexical similarity among the investigated Gbe varieties. The lexical similarity decisions were based on the principles outlined by Blair (1990:31ff), allowing for a few modifications. According to these guidelines, two lexical items are judged to be phonetically similar if at least half of the segments compared are the same or very similar[4] and of the remaining segments at least half are rather similar.[5] Since these guidelines do not take into account the morphemic structure of lexical items, the question presented itself how to deal with the polymorphemic word-structure, i.e. additional morphemes and reduplication, to be found in a fair number of the elicited items. In a paper evaluating different methods in dealing with multimorphemic words in lexicostatistics, Probst (1992) draws attention to two major approaches. The first one requires a thorough morphophonemic analysis, and thus proves rather unfeasible in the context of sociolinguistic language surveys limited in scope and time. The second approach does not require a morphological analysis and is suggested by Schooling (1981). In his survey of French Polynesia, Schooling (1981) compared lexical items as a whole, ignoring reduplication and disregarding additional morphemes that occur in the same position. Given the occurrence of reduplication and additional morphemes in a fair number of the elicited Gbe data and further given the limited scope of the lexicostatistical part of the larger Gbe study, Schooling’s (1981) approach was chosen as the basis for the similarity judgments. Thus, following the guidelines outlined by Schooling (1981), a set of similarity judgment criteria (Criteria Set 1) was established that disregarded differences in the morphological structure of the elicited items:
To explore the effects of different similarity judgment criteria on the lexicostatistical comparison of polymorphemic words, Probst (1992) suggests that a second, more rigorous set of criteria be applied to the same data set. Following these suggestions, a second set of criteria was established that does not ignore differences in the morphological structure: 1. Pairs of complete words were compared. 2. Additional morphemes were included in the analysis. 3. Reduplication was included in the analysis. 4. Class prefixes on nouns were disregarded. Table 2 gives three examples for both similarity judgment criteria sets. The first example considers affixed morphemes, displaying four lexical items for Gloss #20 ‘cow’. For Criteria Set 1, apparently affixed morphemes occurring in the same position were disregarded. Thus, focusing on the morpheme [ɲĩ], the elicited words were considered lexically similar for the Arohun, Ayizo, and Be varieties as well as for the Arohun and Dogbo varieties. However, the items for Dogbo and Be as well as for Dogbo and Ayizo were not considered similar since the additional morphemes do not occur in the same position. Applying the second, more rigorous, criteria set to the same data, only the items for Ayizo and Be were considered lexically similar, whereas the items for the Arohun and Ayizo varieties, the Arohun and Be varieties, the Arohun and Dogbo varieties, as well as for the Ayizo and Dogbo varieties were considered lexically non-similar. Table 2: Similarity judgment criteria sets The second example considers reduplication. For Criteria Set 1, reduplication was disregarded, and thus for gloss #21 ‘goat’ the lexical items were considered similar for the Alada, Awlan, and Kpelen varieties. In contrast, for Criteria Set 2, only the items for Alada and Kpelen were considered lexically similar, whereas for the Alada and Awlan varieties as well as for the Alada and Kpelen varieties they were considered lexically non-similar. Finally, in the third example class prefixes were disregarded for both criteria sets, and thus the elicited items for gloss #6 ‘head’ were considered similar for the Kpelen, Maxi, and Saxwe varieties. Following these examples, the complete Gbe data set was analyzed with both similarity judgment criteria sets being applied to the elicited data. For 84 glosses (84%) of the 100-item word list, the different treatment of reduplication and additional morphemes resulted in different similarity judgment decisions in at least one dialect pair. Employing WORDSURV (Wimbish 1989), a computer program designed for analyzing language survey word lists, the elicited data were organized in two different databases referring to the two different criteria sets.
3.2 Computation of WORDSURV similarity matrices During this second step of the analysis, the similarity judgments arrived at during the first step of the analysis were quantified, with WORDSURV computing two lexical similarity percentage matrices based on a count of shared similar lexical items between each pair of Gbe varieties: word list computation 1 (‘WLC1’) is based on Criteria Set 1 which disregards differences in the morphological structure, and word list computation 2 (‘WLC2’) is based on Criteria Set 2 which does not disregard such differences. In addition to a lexical similarity percentage matrix, WORDSURV computes a range of error for each count, based on the reliability of the word list data which takes into account the researcher’s familiarity with the speech varieties under study, availability of good bilingual informants, and opportunities to double-check elicited items (Wimbish 1989:31). In light of SIL’s language assessment criteria for further interpretation of word-list results, as explained above, the lexical similarity percentages reported in this study refer not to the actual measured degree of similarity; rather, they are the sum of the actual measured degree of similarity plus the upper range of error.[6]
3.3 Paired t-test and correlation analysis To explore whether – based on the different treatment of reduplication and additional morphemes – the different similarity judgment decisions in the 84 glosses of the 100-item word list resulted in significantly different lexical similarity percentages, a paired t-test was conducted. One requirement of a t-test is that the observations be independent. Any pair of lexical similarity percentages, however, that have any variety in common are not independent; even pairs that have no variety in common, but which are based on very closely related varieties are not independent. Therefore, to obtain a set of approximately independent observations, 24 location pairs were chosen such that no location is in more than one pair, with each pair consisting of varieties that are about four “steps” away from each other in the matrix of similarity percentages. In addition, a correlation analysis was conducted to explore whether or not the relationship between the two word-list computations is statistically significant, or in other words whether the two word-list computations indicate the same or different relative relationships between the Gbe speech varieties compared. These analyses were conducted employing the statistical computer package SPSS for Windows, release 9.0 (SPSS Inc. 1998; see also Norušis 1993, Savage 1999, and Simons 1979) and the package R, release 1.9.1 (R-Project, n.d.). To test whether the computed correlation is statistically significantly greater than 0.70, an approximate 95% confidence interval was constructed using the bootstrap method (Efron and Tibshirani 1993). If the lower bound of this interval is greater than 0.70, then the correlation between the two methods is statistically significantly greater than 0.70. Given that, as explained above, the full set of observations is not statistically independent, location pairs used for this significance test were 24 selected pairs, the same as chosen for the paired t-test.
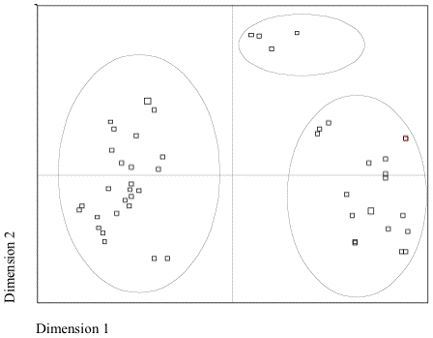
3.4 Multidimensional scalingIn the final step of the analysis, the computed word-list similarity matrices were analyzed with multidimensional scaling (MDS), a statistical procedure designed to analyze the structure of dissimilarity (or similarity) data. The results of this analysis are presented in a perceptual map, as shown in Figure 2, that displays the data as a configuration of points, as on a map, along two, three or more dimensions with the proximity of these points to each other indicating how similar they are. The computed perceptual maps do not directly indicate what the dimensions and configurations refer to but it is left to the researcher to interpret what they represent. Most commonly, ‘dimensional interpretation’ and ‘neighborhood interpretation’ are applied to explain as much of the displayed configuration as possible. ‘Dimensional interpretation’ focuses on large distances along the dimensions of the computed plots and requires the researcher to interpret what the dimensions represent. In contrast, ‘neighborhood interpretation’ focuses on data clustering due to large similarities and requires the researcher to identify groups or neighborhoods of stimuli in the multidimensional space (in Figure 2 the identified neighborhoods are indicated by the ovals). Figure 2: Perceptual MDS map (sample)In addition, MDS provides for each configuration two measures to test the results for reliability and validity: (1) the ‘squared simple correlation’ (RSQ) to determine what proportion of variance of the scaled data can be accounted for by the MDS procedure, and (2) a measure of stress (‘Kruskal’s stress’) to measure how well the derived configuration matches the input data. RSQ values of ≥0.60 are generally considered acceptable, whereas with Kruskal’s measure of stress, small values approaching 0.0 indicate an acceptable goodness of fit. According to Woods et al. (1986) and Scholfield (1991), to name but two, MDS can also be applied to the analysis of linguistic data such as speech sounds or words, respectively, in that it provides a measure of distance or dissimilarity for these data by considering all pairs of observations (see Garrett et al. 1999; Hair et al. 1998; Kruskal and Wish 1978; Manly 1986). Thus, for the current study, MDS was employed as an exploratory data analysis tool to investigate the clustering of the Gbe varieties based on the computed degrees of lexical similarity as indicated by the computed word-list similarity matrices. This analysis was conducted with the statistical computer package SPSS for Windows, release 9.0 (SPSS Inc. 1998; see also Norušis 1993). A two-dimensional analysis was employed with the scaling model based on the default ‘Euclidean distance measure’. With regard to the interpretation of the computed MDS configurations, a combination of neighborhood interpretation and dimensional interpretation was employed, as suggested by Kruskal and Wish (1978). Thus, the computed perceptual maps were investigated as to what the displayed dimensions represent while at the same time taking into account the clustering of the data. Due to the large number of Gbe varieties, the analysis of the complete set of 49 Gbe varieties resulted in a very dense configuration rendering a more detailed interpretation of the computed plots difficult. Thus, for each word-list matrix a total of three MDS plots was computed, the first one including all 49 Gbe varieties, the second one referring to the western and the third one to the eastern Gbe varieties. Given that MDS was employed as an exploratory data analysis tool, no rigorous validation techniques have been applied. However, an initial descriptive analysis of the computed similarity matrices was conducted to compare the MDS findings to the computed lexical similarity percentage matrices. 4. ResultsAn initial descriptive analysis of the two computed similarity matrices indicates a chaining pattern for the entire Gbe cluster. The Gbe speech groups are situated geographically in a contiguous arrangement from the southwestern corner of Nigeria across southern Benin and Togo into Ghana’s Volta region. Thus, the individual Gbe speech groups have contact relationships with the other Gbe groups surrounding them which results in the linguistic convergence of adjoining groups: overall, the investigated Gbe speech forms are marked by relatively small lexical differences between adjoining dialects whereas differences are greater between Gbe varieties at opposing ends of the chain. This chaining pattern is evidenced for both computed word-list similarity matrices in which neighboring groups in the chain are more or less placed in adjoining columns and rows with the highest degrees of lexical similarity occurring on the diagonal and the lowest in the corner with degrees of lexical similarity getting sequentially larger from the corner to the diagonal.
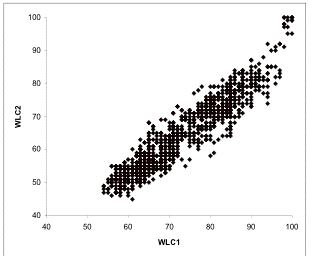
4.1 Statistical Relationships between WLC1 and WLC2Assessing lexical similarity of polymorphemic items, characterized by reduplication and/or additional morphemes, according to the two different similarity judgment criteria sets lead to different similarity judgment decisions for 84 glosses (84%) of the 100-item word list. For the more rigorous similarity judgment criteria set, WLC2, these different decisions resulted in an overall average degree of lexical similarity of 64% with similarity percentage ranges of 45-100%, whereas for WLC1 the overall average degree of lexical similarity was higher with 73% and the range smaller with 54-100% (n=1176), thus yielding an observed difference of 9% between the mean WLC1 percentage and the mean WLC2 percentage. Results of the paired t-test indicate that the observed mean difference between the WLC1 and WLC2 values for the 24 observations (selected as described in Section 3.3) is 9.375 which is statistically significantly different from 0 (p-value < 0.0001). Thus, it can be concluded that the two different similarity judgment criteria sets yield statistically significantly different lexical similarity percentages. Correlation analysis of WLC1 and WLC2 results in a narrow scatter, indicating a linear and positive relationship (see Figure 3). This narrow scatter leads to a high correlation coefficient, r = 0.9395.
r = 0.9395 Figure 3: Scatterplot for word-list computations WLC1 and WLC2 – Complete data set
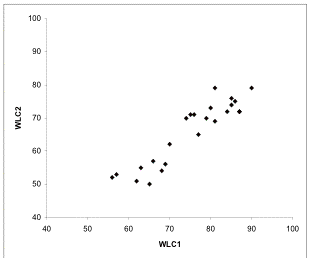
The correlation between WLC1 and WLC2 based on only the 24 observations selected, as described in Section 3.3, is r = 0.9202 (see Figure 4). An approximate 95% confidence interval for the correlation between WLC1 and WLC2 is (0.8751, 0.9583). Since the lower bound of this confidence interval is larger than 0.70, the correlation between the two similarity measures is statistically significantly greater than 0.70.
r = 0.9202 Figure 4: Scatterplot for word-list computations WLC1 and WLC2 – 24 observations
These findings indicate a significant linear relationship between WLC1 and WLC2 with either revealing the same relative distances between the pairs of observed values. Thus, it can be concluded that for the analysis of the Gbe data the two different sets of similarity judgment criteria imply the same relative relationships between the investigated speech varieties. These findings support the conclusion that use of either set of similarity judgment criteria would lead to similar clustering results. To verify this conclusion both word-list computations were further analyzed with multidimensional scaling.
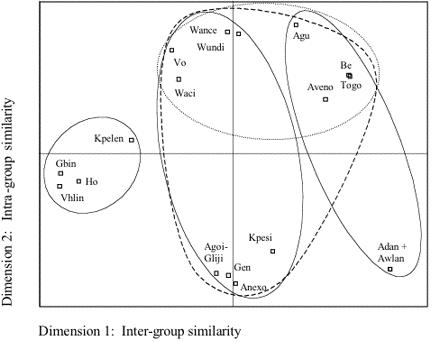
4.2 Clustering of the Gbe language varietiesMultidimensional scaling of the computed word-list matrices results in the MDS plots presented in Figure 5 and Figure 6, with the MDS stress values of 0.187 and 0.246, and the RSQ values of 0.905 and 0.857 for WLC1 and WLC2, respectively, indicating that the derived configurations have an acceptable correlation with the input data. The ovals denote my interpretation of the clusters as indicated by dimensions 1 and 2 of the MDS plots. According to this interpretation, dimension 1 refers to the degree of inter-group similarity of the Gbe varieties, whereas dimension 2 refers to the degree of intra-group similarity for each cluster.
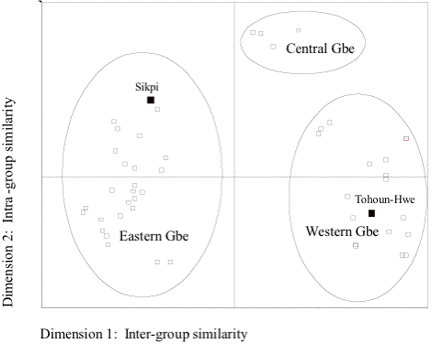
For both computations, displayed in Figure 5 and Figure 6, the MDS findings indicate three distinct clusters of Gbe varieties in terms of their degrees of inter-group similarity. Given their distinct geographical locations, these clusters are – for the purposes of this paper – tentatively referred to as ‘Eastern, Central, and Western Gbe’ (see Figure 1, Section 2). Figure 6: Major Gbe clusters - MDS plot of computation WLC2
In this context, mention needs to be made of the following disparities between the MDS findings and the results indicated by a sociolinguistic survey conducted among two of the 49 investigated Gbe varieties, Sikpi and Tohoun-Hwe. The MDS plots for both word-list computations identify Tohoun-Hwe as a component of the western Gbe cluster and Sikpi as a component of the eastern Gbe cluster (see Figure 5 and figure 6). By contrast, the findings of a more recent and in-depth sociolinguistic survey (including the elicitation of word lists) of the Central Gbe, i.e., Aja communities, conducted in late 1996, clearly identified Sikpi and Tohoun-Hwe as varieties of Aja and, therefore, as components of a central Gbe cluster that consists entirely of Aja varieties (Tompkins and Kluge 2002). Therefore, the results concerning Sikpi and Tohoun-Hwe are discussed together with the results for the remaining Aja varieties in Central Gbe varieties (Section 4.2.2). The placement of the Gbe varieties into three distinct clusters appears to concur with the respective average degrees of intra- and inter-group lexical similarity. For both computations, average degrees of intra-group similarity are higher than average degrees of inter-group similarity, as displayed in Table 3.
* Excluding Sikpi yields an average similarity degree of 67%. Table 3: Average degrees of intra-group and inter-group similarity for the major Gbe clusters
In terms of intra-group similarity, the MDS findings show a rather compact placement of the central Gbe varieties, suggesting little intra-group variation, whereas the placement of the western and eastern Gbe varieties is fairly scattered, thus pointing to higher degrees of intra-group variation. These findings are evidenced by the respective ranges of intra-group lexical similarity, as displayed in Table 3, with the range of similarity degrees for the Central Gbe varieties being smaller than for the Eastern and Western Gbe varieties. Excluding Sikpi and Tohoun-Hwe from the analysis results in the same similarity ranges and average similarity degrees, except for an average inter-group similarity degree of 67% rather than 68% between Eastern and Central Gbe (WLC1). Table 4 gives an overview of the three identified major Gbe clusters and their components; Sikpi and Tohoun-Hwe are grouped together with the central Gbe varieties.
Closer examination of both similarity matrices indicates the same three major Gbe clusters with the same components as the MDS findings. Although lexical similarity percentages differ significantly due to the different similarity judgment criteria sets, a similar pattern emerges for both word-list similarity matrices. For WLC1 and WLC2, average degrees of lexical similarity for the entire Gbe cluster are 73% and 64%, with ranges of 54-100% and 45-100%, respectively (excluding Aja-Sikpi and Aja-Tohoun from the analysis), whereas average degrees of inter-group lexical similarity are lower (WLC1: ≤70%, WLC2: ≤62%), and average degrees of intra-group lexical similarity for the identified three Gbe clusters are higher (WLC1: ≥82%, WLC2: ≥74%). Due to the chaining pattern of the Gbe varieties, though, there is some overlap between the largest degrees of inter-group similarity and the smallest degrees of intra-group similarity. In the following sections, detailed MDS findings for both word-list computations are presented according to their larger geographical clustering, i.e., the western, central, and eastern Gbe varieties.
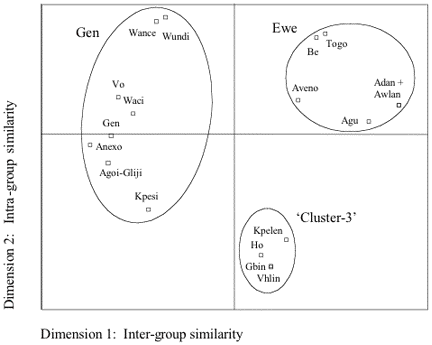
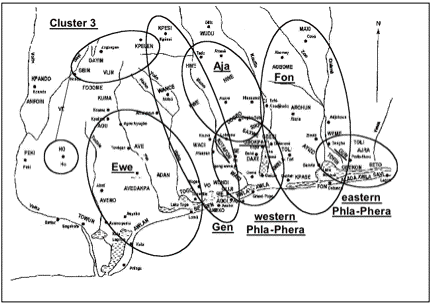
4.2.1 Western Gbe varietiesThe western Gbe varieties are located in Ghana, Togo and Benin between the Volta and Dayi rivers to the west and the Mono river to the east (Capo 1986: map 1a). For the current study, the following western Gbe varieties were included in the analysis: Adan, Agoi/Gliji, Agu, Anexo, Aveno, Awlan, Be, Gbin, Gen, Ho, Kpelen, Kpesi, Togo, Vhlin, Vo, Waci, Wance, and Wundi The MDS results for the Western Gbe varieties are displayed in Figure 7 and Figure 9, with the MDS stress values of 0.208 and 0.256, and RSQ values of 0.787 and 0.665 for WLC1 and WLC2, respectively, indicating that the derived configurations have an acceptable correlation with the input data. The ovals denote my interpretation of the clusters as indicated by dimensions 1 and 2 of the MDS plots. According to this interpretation, dimension 1 refers to the degree of inter-group similarity of the western Gbe varieties, whereas dimension 2 refers to the degree of intra-group similarity for each cluster. For WLC2 (Figure 7), the MDS findings indicate three distinct clusters of the western Gbe varieties in terms of their degrees of inter-group similarity: the Gen and Ewe clusters and a distinct third cluster –preliminarily referred to as ‘Cluster-3’– placed between the Gen and Ewe clusters. The Gen cluster comprises the following varieties: Agoi/Gliji, Anexo, Gen, Kpesi, Vo, Waci, Wance, and Wundi, with the Gen variety already standardized and being used as the language of nonformal education in the southwestern part of Benin. For the Ewe cluster the following varieties are identified by the MDS plot: Adan, Agu, Aveno, Awlan, Be, and Togo, with Awlan the most prestigious variety of Ewe and the basis for Standard Ewe. Finally, Cluster-3 comprises Gbin, Ho, Kpelen, and Vhlin.
The placement of the western Gbe varieties into these three distinct clusters appears to correspond to the more or less distinct geographical locations of these varieties, as indicated in Figure 8. It also appears to concur with the respective average degrees of intra- and inter-group lexical similarity: for the identified clusters average degrees of intra-group similarity are >80% (Ewe: 82%, Gen: 81%, Cluster-3: 90%), whereas average degrees of inter-group lexical similarity are lower, i.e., <75% (Ewe – Gen: 72%, Ewe – Cluster-3: 74%, Gen – Cluster-3: 73%). With regard to their degrees of intra-group similarity, the MDS findings show a rather compact placement of the Cluster-3 varieties, suggesting little intra-group variation, whereas the placement of the Ewe varieties is somewhat less dense, thus pointing to a higher degree of intra-group variation. These findings are evidenced by the respective ranges of intra-group lexical similarity of 81-97% for Cluster-3, and 73-100% for Ewe. Finally, the MDS plot indicates a fairly scattered placement of the Gen varieties with the Wance and Wundi varieties and the Kpesi variety situated the furthest apart, thus suggesting relatively high degrees of intra-group variation, especially between these three varieties. Again, these findings are evidenced by the respective ranges of intra-group lexical similarity of 71-100%. The fairly scattered placement of the Gen varieties with the rather high degree of intra-group variation is due to the somewhat low degrees of lexical similarity between the Wance and Wundi varieties and Kpesi (72% and 71%, respectively), whereas otherwise average degrees of intra-group similarity are higher: 100% between Wance and Wundi, and 84% between the remaining Gen varieties (Agoi/Gliji, Anexo, Gen, Kpesi, Vo, and Waci).
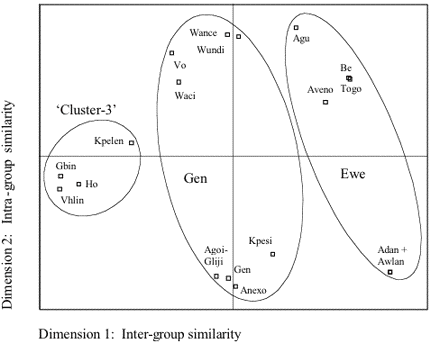
In terms of their degrees of inter-group similarity, the MDS findings for WLC1 indicate the same three western Gbe clusters as indicated for WLC2, i.e., the Gen and Ewe clusters and a distinct third cluster (see Figure 9). Again, this grouping appears to be supported by the computed degrees of lexical similarity: average degrees of inter-group similarity are ≤80% (Ewe – Gen: 80%, Ewe – Cluster-3: 76%, Gen – Cluster-3: 80%) whereas average degrees of intra-group similarity are higher, i.e., >85% (Ewe: 86%, Gen: 87%, Cluster-3: 92%).
Cluster-3 comprises the same Gbin, Ho, Kpelen, and Vhlin varieties, with the MDS findings again showing a rather compact placement of these varieties, thus pointing to a low degree of intra-group variation. These findings are evidenced by the respective ranges of intra-group lexical similarity of 85-98% The Gen cluster, situated between the Cluster-3 and Ewe cluster, comprises the same western Gbe varieties as indicated for computation WLC2. Again, the MDS plot indicates a fairly scattered placement of the Gen varieties, the spread being even wider than for computation WLC2: the Agoi/Gliji, Anexo, Gen, and Kpesi varieties and the Vo, Waci, Wance, and Wundi varieties are situated at opposite ends of the cluster, thus indicating rather high degrees of intra-group variation. Again, these placements appear to concur with the respective computed degrees of lexical similarity. For the subgroupings of the Agoi/Gliji, Anexo, Gen, and Kpesi varieties and the Vo, Waci, Wance, and Wundi varieties average degrees of intra-group similarity are 94% and 91% with ranges of 88-100% and 87-99%, respectively. In contrast, the degrees of lexical similarity between both subgroupings are lower with 83% average inter-group similarity and a range of 80-86%, resulting in the fairly extensive spread of the Gen cluster varieties along dimension 2 as displayed in Figure 9. The Ewe cluster comprises the same western Gbe varieties as attested to by the MDS findings for WLC2, i.e., Adan, Agu, Aveno, Awlan, Be, and Togo. However, whereas for WLC2 the MDS findings show a somewhat dense placement of the Ewe varieties, suggesting only moderate intra-group variation, the MDS plot for WLC1 shows a fairly large scatter of these varieties with the Adan and Awlan varieties and the Agu, Aveno, Be, and Togo placed at opposite poles within the cluster, thus suggesting rather high degrees of intra-group variation. Again, these placements appear to concur with the respective computed degrees of lexical similarity. For the subgroupings of the Adan and Awlan varieties and the Agu, Aveno, Be, and Togo varieties average degrees of intra-group similarity are 100% and 92% (with a range of 86-99%), respectively. In contrast, the degrees of lexical similarity between both subgroupings are lower with 80% average inter-group similarity and a range of 79-81%, which results in the fairly extensive spread of the Ewe cluster varieties as displayed in Figure 9.These rather high degrees of intra-group variation within the Gen and Ewe cluster varieties suggest possible alternative groupings for some of the western Gbe varieties, namely for the Agu, Aveno, Be, and Togo subgrouping (Ewe cluster) and the Vo, Wance, Waci, and Wundi subgrouping (Gen cluster), both of which the MDS plot situates in rather close proximity to each other, as displayed in Figure 10.
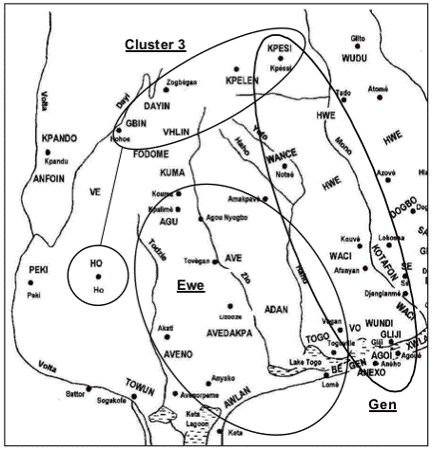
For the Agu, Aveno, Be, and Togo varieties the findings indicate possible groupings with (1) the Adan and Awlan varieties; (2) the Vo, Wance, Waci, and Wundi varieties in a distinct fourth cluster; or (3) with the entire Gen cluster comprising the Agoi/Gliji, Anexo, Gen, Kpesi, Vo, Wance, Waci, and Wundi varieties. These three alternative groupings result in comparable average degrees of intra-group similarity, i.e., 86%, 87%, 85%, respectively. Likewise, the findings indicate possible groupings of the Vo, Wance, Waci, and Wundi varieties with (1) the Agu, Aveno, Be, and Togo varieties; or (2) the Agoi/Gliji, Anexo, Gen, and Kpesi varieties, resulting in the same average degree of 87% intra-group similarity for both indicated alternative groupings. Thus, these findings indicate the following two alternative clusterings of the western Gbe varieties: Cluster-3: Gbin, Ho, Kpelen, and Vhlin Ewe: Adan and Awlan Gen: Agoi/Gliji, Agu, Anexo, Aveno, Be, Gen, Kpesi, Togo, Vo, Wance, Waci, and Wundi Cluster-3: Gbin, Ho, Kpelen, and Vhlin Ewe: Adan and Awlan Gen: Agoi/Gliji, Anexo, Gen, Kpesi Distinct fourth cluster: Agu, Aveno, Be, Togo, Vo, Wance, Waci, and Wundi 4.2.2 Central Gbe varietiesThe MDS findings for both word-list computations indicate a distinct grouping of central Gbe varieties (see Figure 5 and Figure 6). Closer examination of this cluster shows that all components of the central Gbe cluster are in fact varieties of the Aja language. These are located in both Benin and Togo over a large area on both sides of the Mono river. The Aja varieties of Benin are primarily situated in an area bordered by the Kouffo river to the east and the Mono river to the west in Benin’s Mono region, whereas the Togolese Aja varieties are situated west of the Mono river in the southeastern corner of the Plateaux region and the eastern part of the Maritime region (see Figure 11), (Tompkins and Kluge 2002).
Within the context of the SIL study, word lists were elicited in 1988 and 1991 in the Dogbo variety, in the Hwe varieties spoken at Aplahoué, Azovè, Gboto, and Tohoun, and in the Sikpi variety. The MDS plots for both word-list computations indicate Dogbo, Aplahoué-Hwe, Azovè-Hwe, and Gboto-Hwe as components of the central Gbe, i.e., Aja cluster. These findings appear to concur with the respective degrees of lexical similarity with Dogbo, Aplahoué-Hwe, Azovè-Hwe, and Gboto-Hwe sharing fairly high degrees of lexical similarity (WLC1: 86-100%; WLC2: 82-100%). Neither Tohoun-Hwe nor Sikpi, though, are identified as components of the Aja language. Instead, both MDS plots indicate Sikpi as an eastern Gbe variety and Tohoun-Hwe as a western Gbe variety (see Figure 5 and Figure 6). However, in 1996 a more recent and in-depth sociolinguistic study of the Aja communities was conducted that included the administration of sociolinguistic questionnaires as well as the elicitation of word lists in Aja-Dogbo, Aja-Hwe, and Aja-Sikpi (only one Hwe word list was elicited). In addition, word lists were elicited in Aja-Tala and Aja-Tado. The results of the word-list analysis show rather high degrees of lexical similarity of ≥93% among the six Aja varieties, including Sikpi and Tohoun-Hwe (see Table 5). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

|
Aplahoué-Hwe |
||||||
|
97 |
Sikpi |
|||||
|
98 |
97 |
Tohoun-Hwe |
||||
|
94 |
94 |
96 |
Dogbo |
|||
|
94 |
96 |
93 |
93 |
Tado |
||
|
94 |
93 |
95 |
95 |
94 |
Tala |
|
These results indicate that all six varieties are fairly homogeneous with respect to their lexical inventory. In addition, Aja informants stated that Tohoun-Hwe is identical to the Hwe spoken in Aplahoué and Azovè in Benin. Thus, although the results do not include the western Gbe varieties, the findings clearly identify Sikpi and Tohoun-Hwe as varieties of Aja and therefore as components of the central Gbe cluster (see Tompkins and Kluge 2002).
The disparity between the findings of the Aja survey and the findings of the current MDS analysis could be due to the fact that for the study reported here, word lists were elicited from individual L1 speakers of the variety in question, some of whom were not residing in the language area. Thus, the procedure did not allow for the discussion of variants, with group decisions made by L1 speakers resident in the area, as to which form to include in the lists, thus potentially decreasing reliability.
4.2.3 Eastern Gbe varieties
The eastern Gbe varieties are located in Benin and Nigeria east of the Mono river, with the sole exception of a few western Xwla communities located to the west of the Mono river in southeastern Togo, in and around the town of Adamé (see Henson and Kluge 1999). For the current study, the following eastern Gbe varieties were included in the analysis:
Ajra, Agbome, Alada, Arohun, Ayizo, Ci, Daxe, Fon, Gbekon, Gbesi, Gbokpa, Gun, Kotafon, Kpase, Maxi, Movolo, Saxwe, Se, Seto, Tofin, Toli, Weme, Xwela, and eastern and western Xwla
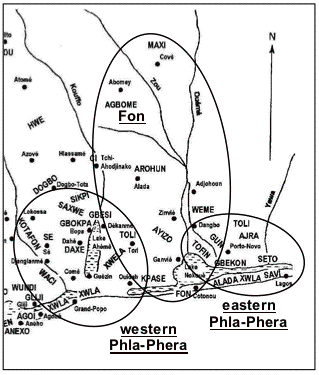
For the Eastern Gbe varieties multidimensional scaling of the two computed word-list matrices results in the MDS plots displayed in Figure 12 and Figure 13, with the MDS stress values of 0.235 and 0.284, and the RSQ values of 0.746 and 0.677 for WLC1 and WLC2, respectively, indicating that the derived configurations have an acceptable correlation with the input data. The ovals indicate my interpretation of the clustering of the eastern Gbe varieties. For the MDS plot of WLC2, though, dimension 1 and dimension 2 do not lend themselves to a clear interpretation. However, the MDS plot suggests a dimensional interpretation along the superimposed dashed lines. Thus, according to my interpretation, dimension 1 and dimension 1’ roughly indicate a perceptual east-west axis with west located to the left and east to the right, whereas both dimension 2 and dimension 2’ represent the extent to which the eastern Gbe varieties are grouped within the Fon or the Phla-Phera clusters.
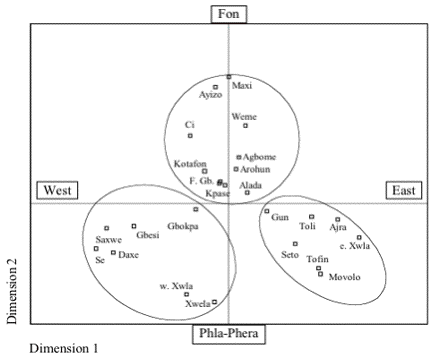
The MDS plots for both word-list computations indicate three distinct clusters along the perceptual Fon – Phla-Phera axis: a Fon cluster situated on the Fon side of this axis, and a western and an eastern Phla-Phera cluster situated at its Phla-Phera side. Along the perceptual east-west axis, the three clusters are situated according to their actual geographical distribution (as displayed in Figure 14) with the western Phla-Phera varieties placed on the western side, the eastern Phla-Phera varieties on the eastern side, and the Fon cluster varieties in the center.
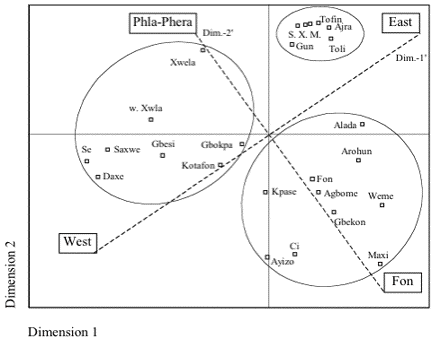
The following varieties are indicated by both MDS plots as components of the Fon cluster: Agbome, Alada, Arohun, Ayizo, Ci, Fon, Gbekon, Kpase, Maxi, and Weme. The MDS plots further suggest Daxe, Gbesi, Gbokpa, Kotafon, Saxwe, Se, Xwela, and western Xwla as components of the western Phla-Phera cluster, and Ajra, Gun, Movolo, Seto, Tofin, and eastern Xwla as components of the eastern Phla-Phera cluster.
In addition, Toli is indicated as a component of the eastern Phla-Phera cluster. According to Capo’s map of the Gbe language area (1986: map 1a), the Toli area is located in Benin’s Atlantique province in and around Tori-Bossito. However, during a more recent and more in-depth sociolinguistic study conducted among the neighboring Ayizo speech communities, it was determined that the speech form of Tori-Bossito is considered to be a variety of Ayizo, i.e., Ayizo-Tori. When asked regarding their comprehension of Toli, the interviewed Ayizo-Tori speakers reported that the speech of Toli speakers who live north of Porto Novo has some phonological differences “when compared with the speech of Tori speakers in the Tori-Bossito region, but these are said to be minor and do not impede comprehension” (Hatfield and McHenry 1998). These Toli communities north of Port-Novo refer to Toli speech communities located in southeastern Benin, in the Ouémé province, more specifically, according to the Atlas Sociolinguistique du Bénin, in the Ajara, Avlanku and Mixlete (Akpro-Misserete) districts (CNL du Bénin 1983), and thus in close geographical proximity to the Tofin and Ajra speech communities. It was here that the Toli word list was elicited. Thus, the map in Figure 14 includes an additional entry for Toli located in the eastern Phla-Phera language area.
The grouping of the eastern Gbe varieties into three distinct clusters appears to be supported by the respective average degrees of inter- and intra-group lexical similarity for both word-list computations.
For WLC1 the lexical similarity matrix indicates for the identified clusters average degrees of inter-group similarity of ≤85% (eastern Phla-Phera – Fon: 84%, eastern Phla-Phera – western Phla-Phera: 81%, Fon – western Phla-Phera: 84%), whereas average degrees of intra-group similarity are higher, i.e., ≥87% (eastern Phla-Phera: 89%, Fon: 90%, western Phla-Phera: 87%). For WLC2 the same pattern emerges, although lexical similarity percentages are overall somewhat lower, with average degrees of inter-group similarity of ≤75% (eastern Phla-Phera – Fon: 75%, eastern Phla-Phera – western Phla-Phera: 71%, Fon – western Phla-Phera: 71%) and average degrees of intra-group similarity of ≥77% (eastern Phla-Phera: 83%, Fon: 78%, western Phla-Phera: 77%).
However, the MDS plot for WLC1 suggests a possible alternative grouping of Gun within the Fon cluster, with Gun being the eastern Phla-Phera variety situated the closest to the Fon cluster varieties. This placement appears to concur with the comparable high degrees of lexical similarity of Gun to the identified eastern Phla-Phera cluster varieties as to the above-mentioned Fon cluster varieties (88-94% versus 81-96%, respectively), thus suggesting a possible alternative grouping of Gun within the later cluster.
Likewise, the MDS findings indicate a possible alternative grouping of the Gbokpa and Kotafon varieties within the Fon cluster rather than within the western Phla-Phera cluster. Although both MDS plots situated Gbokpa and the WLC2-MDS plot also situates Kotafon more towards the western Phla-Phera side of the MDS plot, Gbokpa (according to the MDS plots for WLC1 and WLC2) and Kotafon (according to the MDS plot for WLC2) are also the varieties situated the closest to the Fon cluster varieties. These placements appear to concur with the respective lexical similarity percentages: for Gkokpa degrees of lexical similarity with regard to the identified western Phla-Phera varieties and the above-mentioned Fon cluster varieties are comparable (WLC1: 84-96% versus 84-94%, WLC2: 75-87% versus 73-92%, respectively); likewise, for Kotafon degrees of lexical similarity are comparable with regard to the western Phla-Phera varieties and the Fon cluster varieties (70-80% versus 70-85%, respectively).
Thus, these findings indicate the following alternative grouping of the eastern Gbe varieties: the Agbome, Alada, Arohun, Ayizo, Ci, Fon, Gbekon, Gbokpa, Gun, Kotafon, Kpase, Maxi, and Weme varieties group within the Fon cluster, the Daxe, Gbesi, Saxwe, Se, Xwela, and western Xwla communities within the western Phla-Phera cluster, and the Ajra, Movolo, Seto, Tofin, and eastern Xwla varieties within the eastern Phla-Phera cluster.
5. Discussion and conclusions
5.1 Clustering of the Gbe varieties
The different treatment of the elicited lexical Gbe items according to two different sets of similarity judgment criteria resulted in different similarity judgment decisions for 84 glosses (84%) of the 100-item word list. These different decisions yielded significantly different lexical similarity percentages with consistently lower lexical similarity degrees for WLC2 which is based on a more rigorous set of similarity judgment criteria. At the same time though, the results of the correlation analysis indicated a significant linear relationship between the two computed word-list similarity matrices, thus supporting the conclusion that use of either similarity judgment criteria sets would lead to similar clustering results.
The findings of the MDS analysis of both word-list computations corroborated this conclusion, indicating three major Gbe clusters, comprising the same subgroupings: western Gbe comprising the Ewe, the Gen, and a distinct third cluster, central Gbe referring to the Aja varieties, and eastern Gbe comprising the Fon cluster and a western and eastern Phla-Phera cluster (see Figure 15).
In Table 6, the components of each of the identified Gbe clusters are listed as indicated by the MDS findings for both word-list computations.
|
Western Gbe |
Central Gbe (Aja) |
Eastern Gbe |
|||||
|
WLC1 |
WLC2 |
WLC1 |
WLC2 |
WLC1 |
WLC2 |
||
|
Ewe |
Adan |
Adan |
Dogbo |
Dogbo |
Ajra |
Ajra |
E. P-Phera |
|
Awlan |
Awlan |
Hwe-Aplahoué |
Hwe-Aplahoué |
Movolo |
Toli |
||
|
Agu |
Agu |
Hwe-Azovè |
Hwe-Azovè |
Seto |
Tofin |
||
|
Aveno |
Aveno |
Hwe-Gboto |
Hwe-Gboto |
Tofin |
Movolo |
||
|
Be |
Be |
Hwe-Tohoun |
Hwe-Tohoun |
Toli |
Seto |
||
|
Togo |
Togo |
Sikpi |
Sikpi |
Xwla-e. |
Xwla-e. |
||
|
Gen |
Vo |
Vo |
Gun |
Gun |
|||
|
Waci |
Waci |
Alada |
Alada |
Fon |
|||
|
Wance |
Wance |
Gbekon |
Gbekon |
||||
|
Wundi |
Wundi |
Arohun |
Arohun |
||||
|
Agoi/Gliji |
Agoi/Gliji |
Fon |
Fon |
||||
|
Anexo |
Anexo |
Agbome |
Agbome |
||||
|
Gen |
Gen |
Ci |
Ci |
||||
|
Kpesi |
Kpesi |
Maxi |
Maxi |
||||
|
Cluster-3 |
Kpelen |
Kpelen |
Weme |
Weme |
|||
|
Gbin |
Gbin |
Kpase |
Kpase |
||||
|
Ho |
Ho |
Ayizo |
Ayizo |
||||
|
Vhlin |
Vhlin |
Gbokpa |
Gbokpa |
W. P-Phera |
|||
|
Kotafon |
Kotafon |
||||||
|
Gbesi |
Gbesi |
||||||
|
Xwla-w. |
Xwla-w. |
||||||
|
Xwela |
Xwela |
||||||
|
Saxwe |
Saxwe |
||||||
|
Se |
Se |
||||||
|
Daxe |
Daxe |
||||||
Table 6: Grouping of the Gbe varieties according to the findings of MDS
For both computations, the suggested major groupings and their components concur for all 49 investigated Gbe varieties (100%): 18 western, 6 central, and 25 eastern Gbe varieties (see Table 6).
However, for a number of western and eastern Gbe varieties the MDS findings and the results of the descriptive analysis of the computed word list similarity matrices indicate possible alternative groupings.
With regard to the 18 western Gbe varieties, the findings for WLC1 indicate possible alternative groupings for the Agu, Aveno, Be, Togo, Vo, Waci, Wance, and Wundi varieties. Instead of grouping the Agu, Aveno, Be, and Togo varieties within the Ewe cluster, these varieties could also be grouped (1) in a distinct cluster together with the Vo, Waci, Wance, and Wundi varieties, or (2) within the Gen cluster together with Agoi/Gliji, Anexo, Gen, Kpesi, Vo, Waci, Wance, and Wundi. These alternative groupings would lower the levels of agreement between word-list computations WLC1 and WLC2: for (1) from 18/18 (100%) to 10/18 (56%) identical components, and for (2) to 14/18 (78%) identical components.
For the 25 eastern Gbe varieties, possible alternative groupings are indicated for three varieties, i.e., Gun (computation WLC1), Gbokpa (computations WLC1 and WLC2) and Kotafon (computation WLC2). If these three varieties were to be grouped within the Fon cluster, the groupings for both word-list computations would still concur for 23/25 (92%) of the eastern Gbe varieties.
Overall, the indicated inconsistencies between both word-list computations appear to be due to the fact that WLC1 is based on a less rigorous set of similarity judgment criteria resulting in a similarity matrix and MDS plot that is less clear in identifying similarities and differences, and thus tends to indicate possible alternative groupings. In contrast, WLC2 is based on a more rigorous set of similarity judgment criteria resulting in a similarity matrix and MDS plot that more sharply identifies similarities and differences.
However, in spite of the indicated possible alternative groupings for up to eight western Gbe varieties and up to three eastern Gbe varieties, the levels of agreement between the two word-list computations are still very high. If for the western Gbe cluster the Agu, Aveno, Be, Togo, Vo, Waci, Wance, and Wundi varieties were to be grouped within a distinct cluster, and if for the eastern Gbe cluster the Gbokpa, Gun, or Kotafon varieties were to be grouped within the Fon cluster, the groupings would still concur for 39/49 (80%) of the investigated Gbe varieties. The level of agreement would be even higher if for the western Gbe cluster the Agu, Aveno, Be, and Togo varieties were to be grouped within the Gen cluster (43/49 – 88%).
5.2 Scope and priorities of further sociolinguistic research
In terms of the threshold level of 70% suggested by SIL’s ‘Language assessment criteria’ (International Language Assessment Conference 1990), intra- and inter-group similarity degrees indicated that application of different similarity judgment criteria sets resulted in the same Western, Central and Eastern Gbe clusters and thus would not lead to different recommendations concerning more in-depth research, as far as the second level of the Gbe clustering hierarchy is concerned. As regards more in-depth research within each of the identified three major Gbe clusters, the MDS findings for both word-list computations lend themselves to the following recommendations.
5.2.1 Western Gbe
Given the existence of literature for the Ewe and Gen clusters, further research should give the highest priority to those western Gbe speech communities that are not components of these clusters, i.e., the Cluster-3 varieties. Such research would need to focus on determining whether the Kpelen, Gbin, Ho, and Vhlin varieties could benefit from one of those efforts, or whether an additional development program for Cluster-3 would be beneficial and if so, which variety could serve as the reference variety for this subgrouping. In addition, such research would need to investigate whether existing literature could appropriately be used by all components of the respective Ewe and Gen clusters. Given their geographical location in close neighborhood of the Gen cluster varieties, research among the Be and Togo communities also needs to investigate the extensibility of Gen materials to the Be and Togo communities.
The possible alternative groupings of Agu, Aveno, Be, and Togo within the Gen cluster, as indicated by the MDS findings for WLC1, would suggest further more in-depth research as to whether or not these communities could benefit from the existing Gen cluster literacy efforts. In addition, given the geographical proximity of the Be and Togo varieties to the Ewe cluster varieties, further research would preferably also determine the extensibility of literacy materials among these communities. Thus, the alternative grouping of the Be and Togo varieties would not result in different conclusions as to the scope of further more in-depth research. However, with regard to the Agu and Aveno varieties their alternative grouping within the Gen cluster would lead to a different scope of further research in that extensibility of the Gen cluster literacy efforts would become a major issue whereas otherwise it would not.
Grouping the Agu, Aveno, Be, Togo, Vo, Waci, Wance, and Wundi varieties within a distinct cluster would not result in a different research scope but in assigning higher priority to more in-depth research among these varieties since none of these varieties have undergone language-based development on a larger scale. Thus, further research would need to prioritize these varieties and focus on the question whether these communities could benefit from existing literature efforts in Gen and/or Ewe, or whether an additional development program for this grouping would be beneficial and if so, which variety could serve as the reference variety for this sub-cluster.
5.2.2 Central Gbe
The MDS findings for both word-list computations suggest that more in-depth sociolinguistic research among the Aja speech communities should focus on whether all Aja varieties could benefit from the same Aja literature materials. Such research was carried out in 1996 with the results indicating that in fact all Aja speech communities can benefit from the same literature materials (Tompkins and Kluge 2002).
5.2.3 Eastern Gbe
Given that literature already exists in the Fon and Gun varieties, the highest priority should be given to further research among the western Phla-Phera varieties which are not components of a cluster with existing literature. Such research would need to focus on determining whether these communities could benefit from existing literacy efforts in the Fon cluster and/or – given their geographical proximity to the Gen speaking communities – in the Gen cluster or whether additional language-based development for the western Phla-Phera cluster would be beneficial and if so, which variety could serve as the reference variety for this sub-cluster. More in-depth research among the eastern Gbe varieties also needs to investigate whether existing literature in Fon and Gun could appropriately be used by the remaining Gbe speech communities, i.e., whether the Fon cluster varieties could benefit from existing literature in Fon and whether the eastern Phla-Phera varieties could benefit from existing literature in Gun and/or – given their geographical neighborhood to the Fon speaking communities – Fon.
The indicated possible alternative groupings of Gun within the Fon cluster would not result in a different research scope but in assigning higher priority to more in-depth research among the eastern Phla-Phera varieties since with the exclusion of Gun none of these varieties will have undergone language-based development on a larger scale. Thus, further research needs to prioritize the eastern Phla-Phera varieties and focus on whether these communities could benefit from existing literature efforts in Fon and/or Gun. The alternative grouping of the Gbokpa and Kotafon varieties within the Fon cluster would result in similar conclusions as to determining the extensibility of existing literature in Fon to these communities, except that the priority for conducting such research is lower than for conducting further research among the remaining western Phla-Phera varieties.
5.3 Conclusions
The fact that for both word-list computations average degrees of intra-group lexical similarity were above and inter-group similarity below the indicated threshold of 70% for the identified western, central, and eastern Gbe clusters, lends itself to the conclusion that in terms of SIL’s ‘Language assessment criteria (International Language Assessment Conference 1990), different sets of similarity judgment criteria do not lead to different recommendations concerning the prioritization of more in-depth research as far as the second level of the Gbe clustering hierarchy is concerned.
However, it cannot be concluded that this would be the case for all languages, or even for all West African languages. In contrast, the fact that the calculated similarity percentages differ significantly across both computations suggests the probability that for a different group of speech varieties the application of different criteria sets might result in conflicting average degrees of inter- and intra-group lexical similarity that would subsequently lead to differing recommendations regarding the prioritization of further sociolinguistic research. Such differing recommendations, however, would raise the question as to which of the underlying similarity judgment criteria sets are more appropriate for the investigated language situation.
In light of these ambiguities, the approach chosen for the Gbe data was to take the analysis a step further and apply a combination of techniques to investigate the relative relationships and clustering of the investigated varieties rather than fixating on the indicated threshold level of 70% per se. The findings of correlation analysis and multidimensional scaling suggested that the consistent application of different similarity judgment criteria sets yields compatible conclusions as to the relative relationships and clustering of the investigated varieties as well as to the scope of further research. Further, the findings suggest that the less rigorous similarity judgment criteria bring out similarities and differences less clearly, and thus yield possible alternative groupings which would, overall, affect the degree of priority assigned to the research of the respective varieties, but not the scope of such research.
Given the current lack of an informed, commonly agreed-upon approach to the synchronic analysis of lexical items with polymorphemic word-structure, and further given the limited scope of the larger Gbe study of assessing literacy extensibility, this combination of different techniques was found to offer an expedient approach to the analysis of the rather large Gbe data set without requiring a thorough morphemic analysis which would have been, although preferable, rather unfeasible. More specifically, the comparison of the computed MDS plots, derived from two similarity judgment criteria sets which differ in rigorousness, allowed to verify the suggested groupings and their components, and to identify those Gbe varieties for which the indicated clustering is less clear, thus requiring special attention in more in-depth sociolinguistic research.
Dealing with but a single set of speech varieties, the approach offered here is suggested as a case study for examining the effects of different criteria sets and the usefulness of focusing on the relative relationships and clustering of the investigated varieties by means of multidimensional scaling in establishing priorities for more in-depth sociolinguistic research. Comparable studies in different language situations, applying the techniques suggested here, are needed to verify the validity of this approach chosen for the analysis of the Gbe data.
References
Bennett, Patrick R. and Jan P. Sterk. 1977. South Central Niger-Congo: A reclassification. Studies in African Linguistics 8.241–73.
Blair, Frank. 1990. Survey on a shoestring: A manual for small-scale language surveys. Dallas: Summer Institute of Linguistics and University of Texas.
Brye, Edward and Elizabeth Brye. 2004. Intelligibility testing survey of Bebe and Kemezung and synthesis of sociolinguistic research of the Eastern Beboid cluster. SIL Electronic Survey Reports 2004–011. Dallas: SIL International. Online URL: http://www.sil.org/silesr/2004/silesr2004-011.pdf.
Capo, Hounkpati B.C. 1986. Renaissance du gbe. Une langue de l’Afrique occidentale. Etude critique sur les langues ajatado: l’ewe, le fon, le gen, l’aja, le gun, etc. Université du Bénin. Institut National des Sciences de l’Education. Etudes et Documents de Sciences Humaines. Série A: Etudes, Numéro 13. Lomé.
-----. 1991. A comparative phonology of Gbe. Berlin: Walter de Gruyter.
Commission Nationale de Linguistique du Bénin (CNL du Bénin) 1983. Atlas sociolinguistique du Bénin. Abidjan: Agence de Coopération Culturelle et Technique, and Institut de Linguistique Appliquée.
Dettweiler, Stephen and Sonia Dettweiler. 2003. Sociolinguistic survey of the Duka (Hun-Saare) people. SIL Electronic Survey Reports 2004–004. Dallas: SIL. Online URL: http://www.sil.org/silesr/2003/silesr2003-014.pdf.
Dieu, Michel and Patrick Renaud (eds.) 1983. Atlas linguistique du Cameroun. ALCAM. Paris: Agence de coopération culturelle et technique; Yaoundé : Centre régional de recherche et de documentation sur les traditions orales et pour le développement des langues africaines, Délégation générale à la recherche scientifique et technique, Institut des sciences humaines.
Direction de l’Alphabétisation, République du Bénin, Ministère de la Culture et des Communications (DA) 1992. Séminaire nationale sur la redéfinition des objectifs et stratégies d’alphabétisation et d’éducation des adultes. Rapport final. Cotonou: Presse de Onepi.
Direction de l’Alphabétisation, République du Bénin, Ministère de la Culture et des Communications (DA) no date, a. Nukpinkplon do gungbe me: Wema tintan, 1er livret. Cotonou: DA.
Direction de l’Alphabétisation, République du Bénin, Ministère de la Culture et des Communications (DA) no date, b. Nukpinkplon do gungbe me: Wema aweto, 2ème livret. Cotonou: DA.
Direction de l’Alphabétisation, République du Bénin, Ministère de la Culture et des Communications (DA) no date, c. Nukpinkplon do gungbe me: Wema atontlo, 3ème livret. Cotonou: DA.
Direction Nationale de l’Alphabétisation, Ministère de la Culture et des Communications de la République du Bénin (DNA). no date. Mi va mía kpla woma: Livre de l’élève. Lecture et écriture en waci et gen. Vols. 1, 2 & 3. Benin: DAPR & Comité Provincial de l’Alphabétisation et la Presse Rurale du Mono.
Duthie, Alan S. 1988. Ewe. The languages of Ghana, ed. by Mary E. Kropp Dakubu, 91–101. London: Kegan Paul International for the International African Institute.
Efron, Bradley and Robert J. Tibshirani. 1993. An introduction to the bootstrap. New York: Chapman and Hall.
Garrett, Peter, Nikolas Coupland, and Angie Williams. 1999. Evaluating dialect in discourse: Teachers’ and teenagers’ responses to young English speakers in Wales. Language in Society 28.321–54. doi:10.1017/s0047404599003012
Gordon, Raymond G. ed. 2005. Ethnologue: Languages of the world, Fifteenth Edition. Dallas: SIL International. Online URL: http://www.ethnologue.com.
Grimes, Barbara F., ed. 2000.
Grimes, Joseph E. 1988. Correlations between vocabulary similarity and intelligibility. Notes on Linguistics 41.19–33.
Gudschinsky, Sarah C. 1955. Lexico-statistical skewing from dialect borrowing. International Journal of American Linguistics 21.138–49. doi:10.1086/464322
-----. 1956. The ABC’s of lexicostatistics (glottochronology). Word 12.175–210.
Hair, Joseph F., Rolph E. Anderson, Ronald L. Tatham, and William C. Black. 1998. Multivariate data analysis. London: Prentice-Hall International, Inc.
Harrison, Byron, Annette Harrison, and Michael J. Rueck. 1999. Southern Songhay speech varieties in Niger: A sociolinguistic survey of the Zarma, Songhay, Kurtey, Wogo, and Dendi peoples of Niger. SIL Electronic Survey Reports 1999-004. Dallas: SIL International. Online URL: http://www.sil.org/silesr/1999/004/zarmarpt4.pdf.
Hatfield, Deborah H. and Michael M. McHenry. 1998. A sociolinguistic survey of the Ayizo language area. Cotonou, Benin: SIL International. ms.
Henson, Bonnie J. and Angela Kluge. 1999. A sociolinguistic survey of the Xwla language area. Cotonou, Benin: SIL International. ms.
Hochstetler, J. Lee, Jude A. Durieux, and Evelin I. K. Durieux-Boon. 2004. Sociolinguistic survey of the Dogon language area. SIL Electronic Survey Reports 2004–004. Dallas: SIL International. Online URL: http://www.sil.org/silesr/2004/silesr2004-004.pdf.
International Language Assessment Conference. 1990. Language assessment criteria: Conference recommendations. Proceedings of the Summer Institute of Linguistics International Language Assessment Conference, Horsleys Green, 23–31 May 1989, ed. by Gloria E. Kindell, 27–29. Dallas: SIL.
Kluge, Angela. 2000. The Gbe language varieties of West Africa: A quantitative analysis of lexical and grammatical features. Unpublished MA thesis. Cardiff: University of Wales, College of Cardiff.
-----. forthcoming. Qualitative and quantitative analysis of grammatical features elicited among the Gbe language varieties of West Africa. Journal of African Languages and Linguistics. doi:10.1515/jall.2006.004
Kruskal, Joseph B. and Myron Wish. 1978. Multidimensional scaling. Beverley Hills: Sage Publications.
Manly, Bryan F.J. 1986. Multivariate statistical methods: A primer. London, New-York: Chapman and Hall.
Norušis, Marija J. 1993. SPSS for Windows: Professional statistics. Release 6.0. Chicago: SPSS Inc.
Probst, Ulrich. 1992. Multimorphemic words in lexicostatistics: An evaluation on use and limitations of different approaches. Paper presented at the SIL Survey Course, Horsleys Green, UK. ms.
R-Project. no date. The R project for statistical computing. Online URL: http://www.r-project.org.
Sanders, Arden G. 1977. Guidelines for conducting a lexicostatistics survey in Papua New Guinea. Language planning and survey techniques, ed. by Richard Loving and Gary F. Simons, 21–41. Ukarumpa, PNG: Summer Institute of Linguistics.
Saussure, Ferdinand de. 1959. Course in general linguistics. London: Peter Owen Limited.
Savage, Dale. 1999. Understanding correlation. Windows on bilingualism, ed. by Eugene H. Casad, 117–146. Dallas: The Summer Institute of Linguistics and The University of Texas at Arlington.
Scholfield, Phil. 1991. Statistics in linguistics. Annual Review of Anthropology 20.377–93. doi:10.1146/annurev.anthro.20.1.377
Schooling, Stephen J. 1981. A linguistic and sociolinguistic survey of French Polynesia. Hamilton, New Zealand: Summer Institute of Linguistics.
Simons, Gary F. 1977. The role of purpose and perspective in planning a language survey. Language planning and survey techniques, ed. by Richard Loving and Gary F. Simons (eds.), 9–20. Ukarumpa, PNG: Summer Institute of Linguistics.
-----. 1979. Language variation and limits to communication. (Technical Report 3.) Ithaca, NY: Department of Modern Languages and Linguistics, Cornell University. (Reprinted 1983 by Summer Institute of Linguistics, Dallas, TX.)
SPSS Inc. 1998. SPSS for Windows: Release 9.0. SPSS, Inc., 1989–1999.
Stewart, John M. 1989. Kwa. The Niger-Congo languages, ed. by John, Bendor-Samuel, 217–245. Lanham, MD: The University Press of America.
Swadesh, Morris. 1955. Toward greater accuracy in lexicostatistical dating. International Journal of American Linguistics 21.121–37. doi:10.1086/464321
Tompkins, Barbara and Angela Kluge. 2002. Sociolinguistic survey of the Aja language area. SIL Electronic Survey Reports 2002–020. Dallas: SIL. Online URL: http://www.sil.org/silesr/2002/020/SILESR2002-020.PDF.
Wimbish, John. 1989. WORDSURV: A program for analyzing language survey word lists. Dallas: Summer Institute of Linguistics.
Woods, Anthony, Paul Fletcher, and Arthur Hughes. 1986. Statistics in language studies. Cambridge: Cambridge University Press.
[1]I would like to thank M. Paul Lewis, Richard J. Nivens and Ramzi Nahhas of SIL International for their helpful comments on this paper. Nahhas, in particular, discussed various aspects of paired t-test and correlation analysis with me.
[2]In Kluge (forthcoming) I described the Gbe situation in some detail. The following section summarizes and refers to that description.
[3]Capo (1986) does not list a distinct Fon variety (seeTable 1). For the current study, however, a word list was elicited in the Fon variety (see Section 4.2).
[4]Nonvocalic segments are either exact matches or else they differ by only one phonological feature and this difference is attested in three pairs, and vowels differ by only one phonological feature.
[5]Nonvocalic segments differ by only one phonological feature but are not attested in three pairs; vowels differ by two or more phonological features.
[6]Thus, if A and B share 50% lexical similarity and the range of error is +/-25% then the actual lexical similarity could by any where from 25-75%. And if A and C share 68% lexical similarity and the range of error is +/-7% then the actual lexical similarity would by any where from 61-75%. In both cases ‘75%’ refers to ‘upper range of error’ and, based on SIL’s criteria, intelligibility testing between A and B and A and C would need to be considered.
[ Home | Current Issue | Browse the Archive | Search the Site | Submission Information | Register for Updates | About | Editorial Board | Site Map | Help ]
Published by the Dartmouth College Library.
|